新闻
当营销速度遇上数据延迟的“玻璃墙”
作者:创源无限技术负责人

凌晨1点,一位高端美妆品牌的数据团队刚刚完成当日用户标签的批量更新。他们根据“过去24小时加购但未下单”的规则,圈选出潜在客户,准备在上午10点推送一张限时优惠券。然而,他们不知道的是,其中一位核心客户“李小姐”在凌晨0:50加购了最新款精华液,因网络问题支付失败,随后在凌晨0:55重新尝试并成功下单——她已不再是“未下单用户”。
上午9点,运营人员按计划推送了优惠券。李小姐惊讶地发现自己刚全价购买的产品竟然在半小时后就“打折”了。困惑转化为不满,一条投诉悄然生成,客户体验出现裂痕。
这个场景,是传统“离线计算”标签体系下每天都在发生的微小悲剧。在客户决策以秒计算的今天,我们的标签系统却仍以“天”为单位运行,业务需求与数据能力之间横亘着一道“玻璃墙”——看得见需求,却无法及时触及。
今天,我们想分享如何用全新的实时标签引擎,打破这堵墙。


在相当长的时间里,企业的用户标签系统遵循着这样的工作节奏:
每天凌晨1点,数据平台启动ETL作业,从各业务系统抽取前一日数据;
凌晨3点,开始执行复杂的标签计算逻辑;
早晨6点,标签计算完成,导入标签库;
上午9点,运营人员终于可以使用“新鲜”的昨日标签。
这套体系存在三个结构性痛点:
痛点一:数据时效性致命伤
当标签以T+1的频率更新时,意味着我们永远基于“过去”做决策。在电商大促、内容推荐、风险控制等场景中,这种延迟是致命的——用户流失可能发生在分钟级别,而我们的应对却在24小时后。
痛点二:资源利用的“潮汐现象”
计算资源在凌晨达到峰值,白天大量闲置。为了应对凌晨数小时的批量计算,企业不得不维持庞大的计算集群,资源利用率通常低于30%。
痛点三:业务灵活性的枷锁
“新增一个标签需要重新开发ETL作业”是常见瓶颈。当业务方提出“我想圈选过去1小时内三次搜索同一商品但未购买的用户”时,数据团队的常见答复是:“这个需求需要排期,下周可以上线。”
更令人沮丧的是,即使标签计算完成,其应用路径也充满障碍。标签系统与推荐系统、广告平台、客服系统之间,往往需要通过复杂的接口同步和数据导出导入,形成一个个“数据孤岛”,响应时间进一步拉长。、
要解决上述痛点,必须从架构层面进行根本性革新。我们的新标签技术体系,围绕三个核心组件重构:
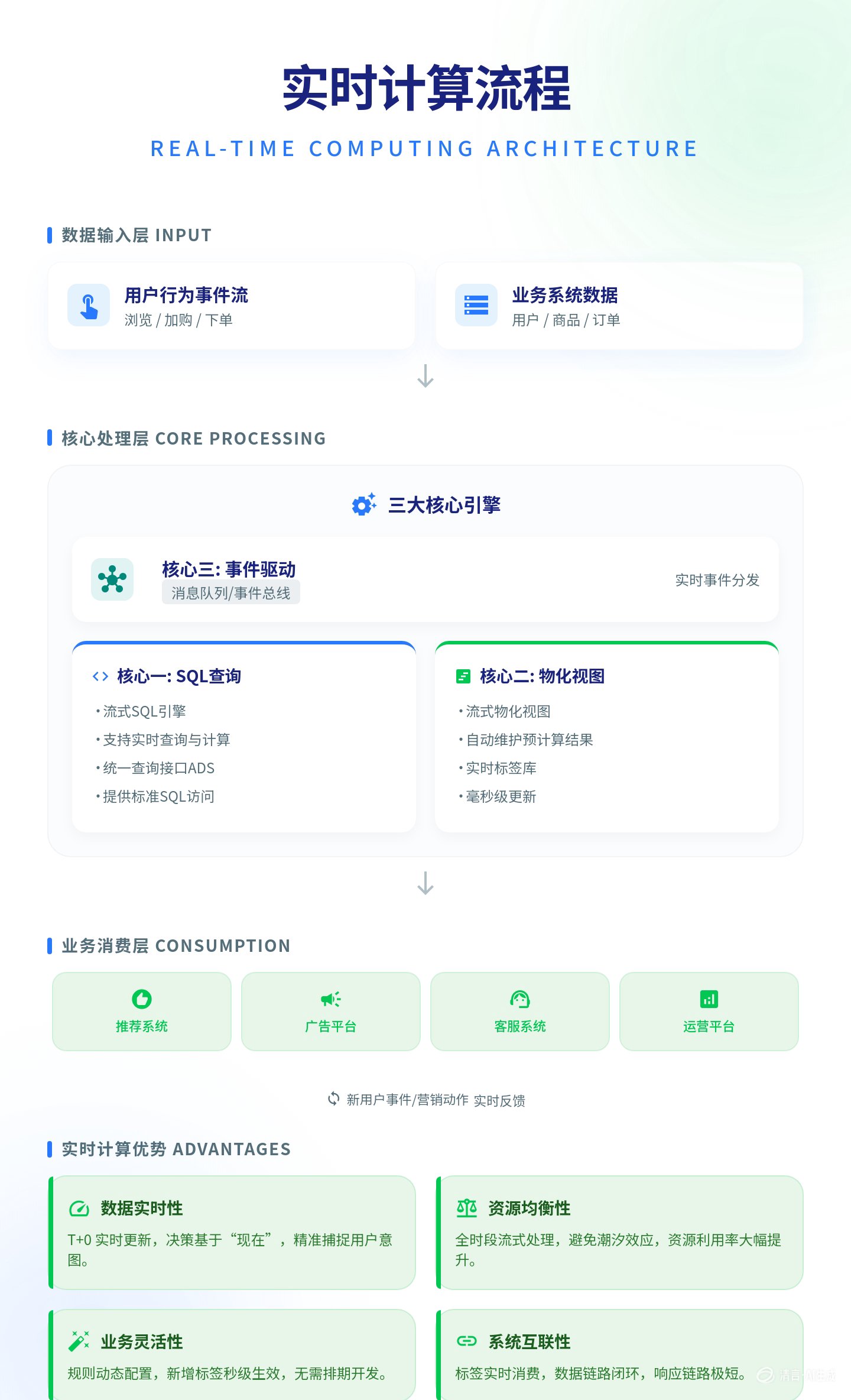
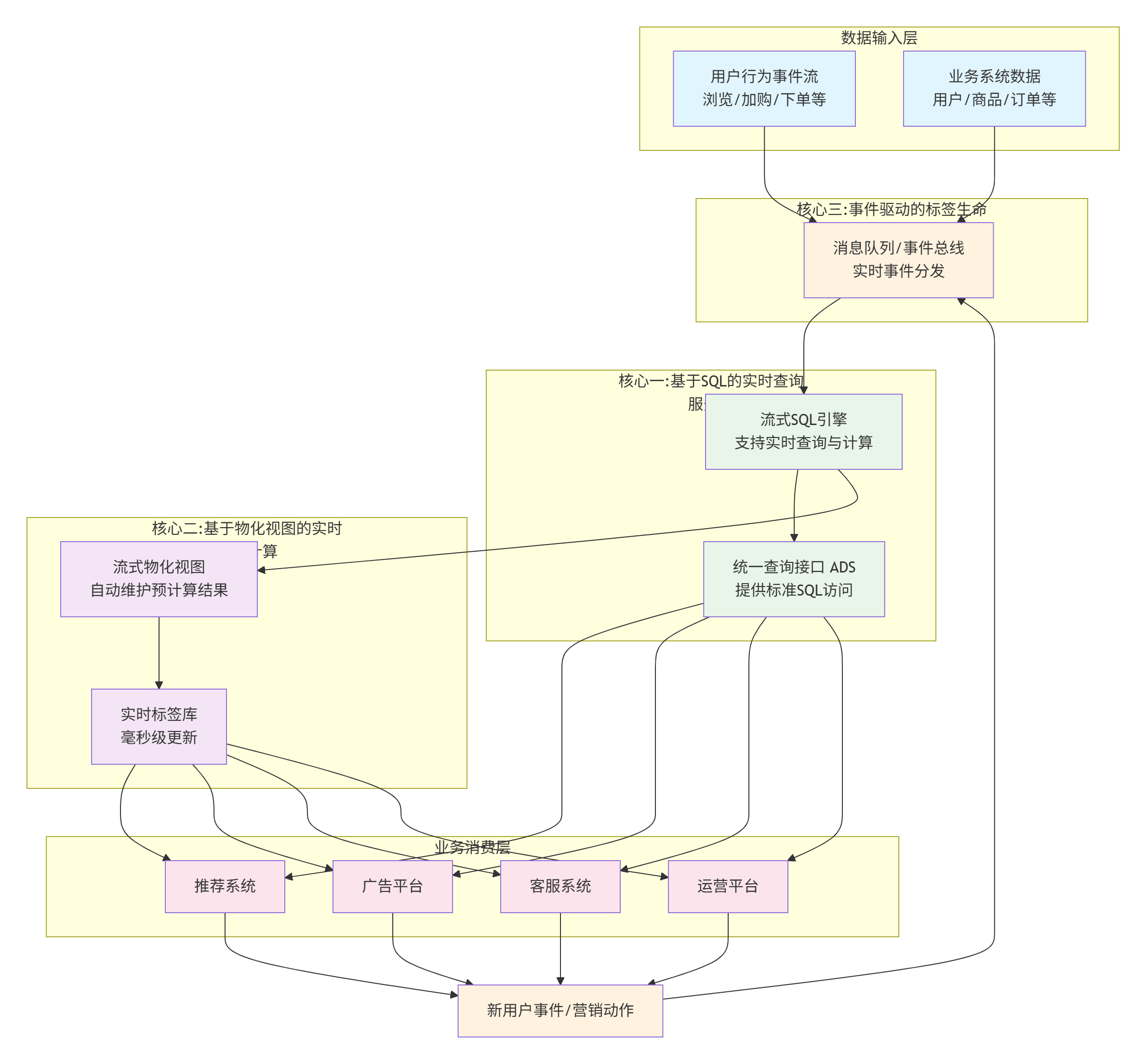
传统架构中,应用层需要的数据必须预先计算好并导出。而在新体系中,我们基于流式SQL构建了一个统一的实时查询服务层。
技术实现:
-- 实时查询过去1小时加购未下单用户
SELECT user_id,
COUNT(DISTINCT product_id) as cart_items_count,
MAX(event_time) as last_cart_time
FROM user_events_stream
WHERE event_type = 'add_to_cart'
AND user_id NOT IN (
SELECT DISTINCT user_id
FROM order_stream
WHERE order_time > NOW() - INTERVAL 1 HOUR
)
AND event_time > NOW() - INTERVAL 1 HOUR
GROUP BY user_id
HAVING cart_items_count >= 1;这个简单的SQL可以实时执行,返回当前时刻的精确结果,无需等待凌晨的批量作业。基于此,我们构建的实时ADS(应用数据服务)层,让业务系统能够像查询数据库一样,实时查询最细粒度的用户行为。
对于需要频繁查询的共性标签,我们引入流式物化视图技术。物化视图会自动维护预计算的结果,但与传统物化视图不同,流式物化视图是实时更新的。
技术实现:
-- 创建实时活跃用户标签物化视图
CREATE MATERIALIZED VIEW realtime_active_users_view into realtime_active_users (
user_id string,
session_count_last_7d int,
active_last_1d decimal,
last_active_time datetime
) AS
SELECT user_id,
COUNT(*) as session_count_last_7d,
SUM(CASE WHEN event_time > NOW() - INTERVAL 1 DAY THEN 1 ELSE 0 END) as active_last_1d,
MAX(event_time) as last_active_time
FROM user_events_stream
WHERE event_time > NOW() - INTERVAL 7 DAYS
GROUP BY user_id;
-- 此视图会自动实时更新
-- 业务方可以像查询普通表一样使用它
SELECT * FROM realtime_active_users
WHERE active_last_1d = 1
AND session_count_last_7d >= 3;核心突破: 所有基于事件流的标签规则,都可以通过SQL定义并实现实时计算。无论是简单的属性标签(如“性别=女”),还是复杂的行为序列标签(如“浏览A商品后30分钟内搜索B商品”),都遵循同一套逻辑体系。
在新体系中,标签不再是“静态的快照”,而是“动态的状态”。我们构建了完整的事件驱动机制:
标签实时生成:用户行为事件触发 → 流处理引擎计算 → 标签即时更新
标签实时消费:标签更新事件 → 消息队列推送 → 下游系统实时响应
标签实时反馈:营销动作产生新事件 → 重新进入标签计算循环
这个闭环让标签从“数据记录”变成了“业务触发器”。
传统流程:
用户浏览商品 → 行为记录到数据库 → 凌晨批量计算用户兴趣标签 → 第二天推荐系统使用“昨日兴趣”做推荐
实时标签流程:
用户浏览商品A(13:00:00)→ 事件进入流处理平台(13:00:01)→ 实时计算用户当前兴趣向量(13:00:02)→ 推荐接口获取最新兴趣标签(13:00:03)→ 推荐相似商品B(13:00:04)
技术实现:
-- 实时兴趣标签计算
CREATE MATERIALIZED VIEW realtime_user_interest_view intorealtime_user_interest(
user_id string,
interest_score decimal,
) AS
SELECT
behaviors.user_id,
meta.item_category,
SUM(
CASE behaviors.event_type
WHEN 'view' THEN 0.3 * behaviors.time_weight
WHEN 'click' THEN 0.5 * behaviors.time_weight
WHEN 'purchase' THEN 1.0 * behaviors.time_weight
END
) as interest_score
FROM (
-- 内层子查询:计算时间衰减权重
SELECT
user_id,
item_id,
event_type,
event_time,
EXP(-EXTRACT(EPOCH FROM (NOW() - event_time))/3600) as time_weight
FROM user_behavior_stream
WHERE event_time > NOW() - INTERVAL 2 HOUR
AND event_type IN ('view', 'click', 'purchase')
) AS behaviors
JOIN item_metadata AS meta ON behaviors.item_id = meta.id
GROUP BY behaviors.user_id, meta.item_category
ORDER BY interest_score DESC;效果对比:
某时尚电商接入实时标签后,推荐点击率提升37%,关键指标是“当天浏览商品的当天购买转化率”提升了2.8倍。当用户刚对某类商品表现出兴趣时,系统就能立即响应,而不是等到“明天再说”。
在效果广告领域,每一次曝光的价值取决于对用户的实时理解。我们的技术架构实现了与广告平台的无缝集成:
技术实现:
-- 实时广告标签计算与推送
CREATE STREAM ad_targeting_signals(
user_id string,
signal_type string,
signal_value string,
signal_time datetime
);
insert into ad_targeting_signals(user_id,signal_type,signal_value,signal_time)
SELECT user_id,
'high_value_user' as signal_type,
TRUE as signal_value,
NOW() as signal_time
FROM realtime_user_lifetime_value
WHERE predicted_ltv > 1000
AND update_time > NOW() - INTERVAL 5 MINUTE
UNION ALL
SELECT user_id,
'cart_abandoner' as signal_type,
TRUE as signal_value,
NOW() as signal_time
FROM realtime_cart_events
WHERE status = 'abandoned'
AND abandon_time > NOW() - INTERVAL 1 HOUR;
-- 将此流实时推送到广告平台
CREATE STREAM ad_platform_sink
(
`raw` string
)
ENGINE = ExternalStream
SETTINGS type = 'kafka', brokers = 'localhost:9092', topic = 'cs_topic', security_protocol = 'PLAINTEXT', data_format = 'RawBLOB', skip_ssl_cert_check = 'false', one_message_per_row = 'true';
insert into ad_platform_sink(raw) SELECT * FROM ad_targeting_signals实际案例:
某教育客户在广告投放中,原先使用每日同步的标签数据,用户从完成“高意向行为”到被标记为“高意向用户”平均延迟6-8小时。接入实时标签推送后,延迟降低到200毫秒内。在竞争激烈的关键词竞价中,这一优势让他们在优质流量获取成本上降低了22%。
传统AI预测标签往往面临尴尬:模型预测用户明天有80%概率流失,但预测结果要到明天才能被运营系统使用。我们打通了这一瓶颈:
端到端流程:
实时特征工程:从事件流中实时计算模型所需特征
实时预测:特征输入在线模型服务,获取预测结果
实时标签化:预测结果作为标签实时写入标签库
实时响应:运营系统基于实时预测标签立即采取行动
技术架构:
用户行为事件流 → 实时特征计算(流式SQL) → 特征向量
↓
在线预测服务(接收特征向量,返回预测结果) → 预测结果流
↓
预测结果作为标签实时更新 → 实时标签库
↓
风控/营销系统实时订阅 → 即时干预实战效果:
某金融科技公司使用此架构实现实时欺诈预测。从用户行为发生,到被标记为“高风险”,到风控系统拦截,端到端延迟低于500毫秒。相比之前的T+1批量模式,可疑交易识别率提升3.4倍,且能够在欺诈发生过程中实时拦截,而不仅是事后追溯。
流批一体统一处理
我们基于Timeplus流批一体平台,对实时数据和历史数据使用同一套SQL语义进行处理。这意味着开发人员只需学习一种语法,就能处理从实时毫秒级到历史数年的全时段数据。
分层标签体系
原始事件层:毫秒级事件数据,保留最细粒度信息
实时特征层:基于事件流实时计算的用户特征
标签服务层:提供统一标签查询接口,支持实时和历史查询
应用输出层:面向不同业务系统的定制化标签输出
状态管理与一致性
实时标签的核心挑战之一是状态管理。我们采用以下策略:
短期状态:使用流处理引擎内置状态(如Timeplus的状态管理)
长期状态:与外部数据库(如ClickHouse、Doris,mysql,pgsql等)结合
一致性保证:基于事件时间的处理,配合水印机制处理乱序数据
模式一:实时聚合标签
-- 实时计算用户活跃度标签
CREATE MATERIALIZED VIEW user_activity_level_view into user_activity_level(
user_id string,
event_count_1h int,
distinct_event_types_1h int,
last_page_1h string,
activity_score decimal
) AS
SELECT
user_id,
COUNT(*) as event_count_1h,
COUNT(DISTINCT event_type) as distinct_event_types_1h,
MAX_BY(page_url, event_time) as last_page_1h,
-- 活跃度评分公式
LOG(10, COUNT(*) + 1) * 0.4 +
COUNT(DISTINCT event_type) * 0.3 +
(CASE WHEN MAX(event_time) > NOW() - INTERVAL 10 MINUTES THEN 0.3 ELSE 0 END) as activity_score
FROM user_event_stream
WHERE event_time > NOW() - INTERVAL 1 HOUR
GROUP BY user_id
HAVING COUNT(*) > 0;模式二:时序行为模式标签
-- 识别“浏览-搜索-加购”行为序列
CREATE MATERIALIZED VIEW browse_search_cart_sequence_view into browse_search_cart_sequence(
user_id string,
tag_name string
) AS
SELECT
user_id,
'completed_browse_search_cart_sequence' as tag_name,
TRUE as tag_value,
NOW() as tag_time
FROM (
SELECT
user_id,
event_type,
event_time,
LAG(event_type, 1) OVER w as prev_event_type,
LAG(event_type, 2) OVER w as prev_event_type_2,
LAG(event_time, 2) OVER w as prev_event_time_2
FROM user_event_stream
WHERE event_time > NOW() - INTERVAL 30 MINUTE
WINDOW w AS (PARTITION BY user_id ORDER BY event_time)
) AS sequences
WHERE event_type = 'add_to_cart'
AND prev_event_type = 'search'
AND prev_event_type_2 = 'browse'
AND event_time - prev_event_time_2 < INTERVAL 30 MINUTE;模式三:实时异常检测标签
-- 实时检测异常登录行为
CREATE MATERIALIZED VIEW abnormal_login_behavior_view into abnormal_login_behavior(
user_id string,
tag_name string
) AS
SELECT
user_id,
'suspicious_login_behavior' as tag_name,
TRUE as tag_value,
NOW() as detection_time,
JSON_OBJECT(
'reason', CASE
WHEN login_count_10min > 5 THEN 'too_many_logins'
WHEN distinct_ips_10min > 3 THEN 'multiple_ip_addresses'
ELSE 'other_suspicion'
END,
'login_count', login_count_10min,
'ip_count', distinct_ips_10min
) as tag_metadata
FROM (
SELECT
user_id,
device_id,
COUNT(*) as login_count_10min,
COUNT(DISTINCT ip_address) as distinct_ips_10min
FROM login_event_stream
WHERE event_time > NOW() - INTERVAL 10 MINUTE
AND login_status = 'success'
GROUP BY user_id, device_id
HAVING COUNT(*) > 5 OR COUNT(DISTINCT ip_address) > 3
) AS suspicious_users;分层物化视图策略
高频查询标签:全量物化,秒级更新
中频查询标签:部分聚合物化,分钟级更新
低频查询标签:按需计算,不预物化
智能分区与索引
-- 按用户ID和标签类别分区
CREATE TABLE user_tags (
user_id BIGINT,
tag_category VARCHAR(50),
tag_name VARCHAR(200),
tag_value VARCHAR(1000),
update_time TIMESTAMP,
expire_time TIMESTAMP
) PARTITION BY (user_id % 100, tag_category);
-- 为高频查询创建索引
CREATE INDEX idx_user_active_tags
ON user_tags(tag_name, update_time)
WHERE expire_time > NOW();标签生命周期管理
-- 自动过期临时标签
CREATE PIPELINE cleanup_expired_tags
AS
DELETE FROM user_tags
WHERE expire_time <= NOW() - INTERVAL 1 HOUR
SCHEDULED EVERY 5 MINUTES;营销效率提升
实时营销活动响应时间:24小时 → 1秒内
个性化推荐点击率提升:+15%~40%
营销自动化流程执行效率:+300%
运营成本降低
计算资源需求:-60%(消除凌晨批量计算峰值)
数据工程人力投入:-40%(SQL开发替代ETL开发)
数据到决策的延迟:24小时 → 实时
风险控制增强
欺诈检测实时性:T+1 → 500毫秒内
异常行为发现时间:数小时 → 实时
风险事件漏报率:-70%
大量的实践经验告诉我我们,实时标签引擎的演进,本质上是从“数据记录系统”到“业务神经系统”的转变。传统标签体系像企业的“历史档案馆”,保存着过去的记录;而实时标签体系则像“中枢神经系统”,感知每一刻的变化,并立即做出反应。
在用户耐心以秒计算、竞争边界日渐模糊的今天,企业的数据能力必须实现从“离线”到“实时”的跃迁。这不仅是技术的升级,更是业务模式的进化。
当我们能够对每一个用户行为做出毫秒级的理解与响应时,我们提供的就不再是标准化的产品和服务,而是真正个性化的体验。用户的每次点击、每次浏览、每次停留,都成为我们理解他们、服务他们的机会窗口。
实时标签技术正在重新定义客户互动的速度与精度。那些率先完成这一跃迁的企业,将在个性化时代获得决定性优势。
现在,是时候让您的标签系统告别“T+1”,进入“T+0”的实时时代了。
